Abstract
Speech-driven 3D facial animation has gained significant attention for its ability to create realistic and expressive facial animations in 3D space based on speech.
Landmarks can comprehensively and efficiently describe speech-related movements.
However, existing methods do not fully exploit the implicit context information of speech, but rather simplify using single-level (i. e., frame-level) speech features to learn landmarks and
then map them into the entire facial animation.
They largely overlooked the relationships between landmarks in distinct temporal regions and different-level speech features (e. g., phonemes, words, and utterances), resulting in over-smoothed
facial movements. In the present work, we propose a novel framework, namely Hierarchical Speech feature-based 3D Talking head animation (HiSTalk),
to explore the correlations between different-level speech features and facial landmarks.
This framework consists of two modules: Hierarchical Speech Features to Sparse landmark displacements (HSF2S) and Sparse landmarks to Dense landmarks (S2D).
Specifically, HSF2S is a hierarchical structure-based encoder to establish the correlations between sparse facial landmark displacements and different-level speech features;
then, S2D -- a Transformer-based multi-branch fusion decoder -- generates the corresponding dense motion fields based on these sparse landmarks.
Furthermore, HSF2S includes a squeeze and extraction weight generation mechanism to calculate the contributions of different-level speech features to landmarks,
and S2D includes an attention-based fusion operation to synthesize dense facial deformations, which ensures plausible lip synchronization and facial activities.
Extensive qualitative and quantitative experiments and user studies indicate that our method outperforms existing state-of-the-art methods.
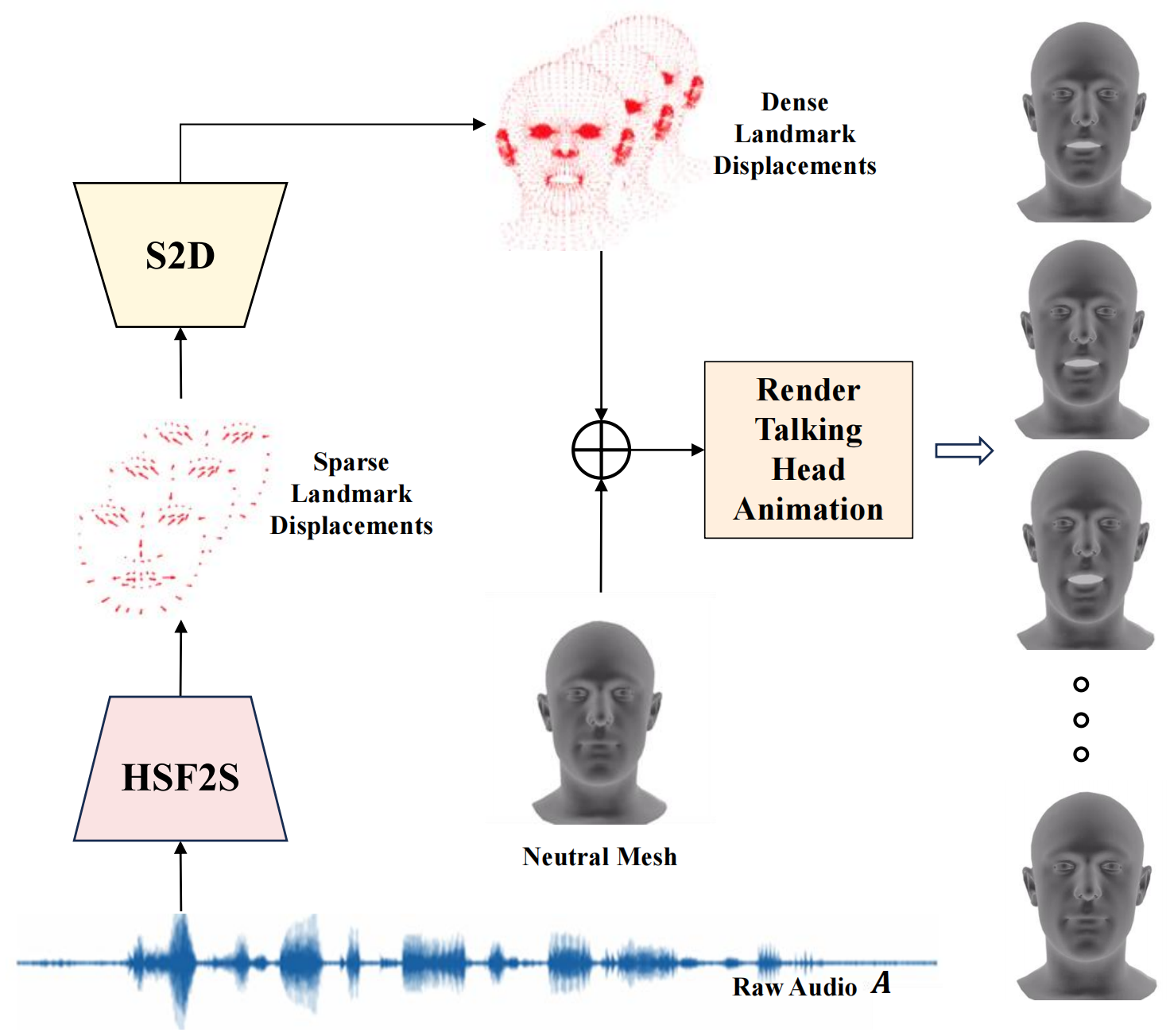
Given a speech signal as input, our framework HiSTalk can generate realistic 3D talking heads through the Hierarchical Speech Features to Sparse Landmarks (HSF2S)
module and the Sparse Landmarks to Dense Landmarks Displacements (S2D) module.
Proposed Method
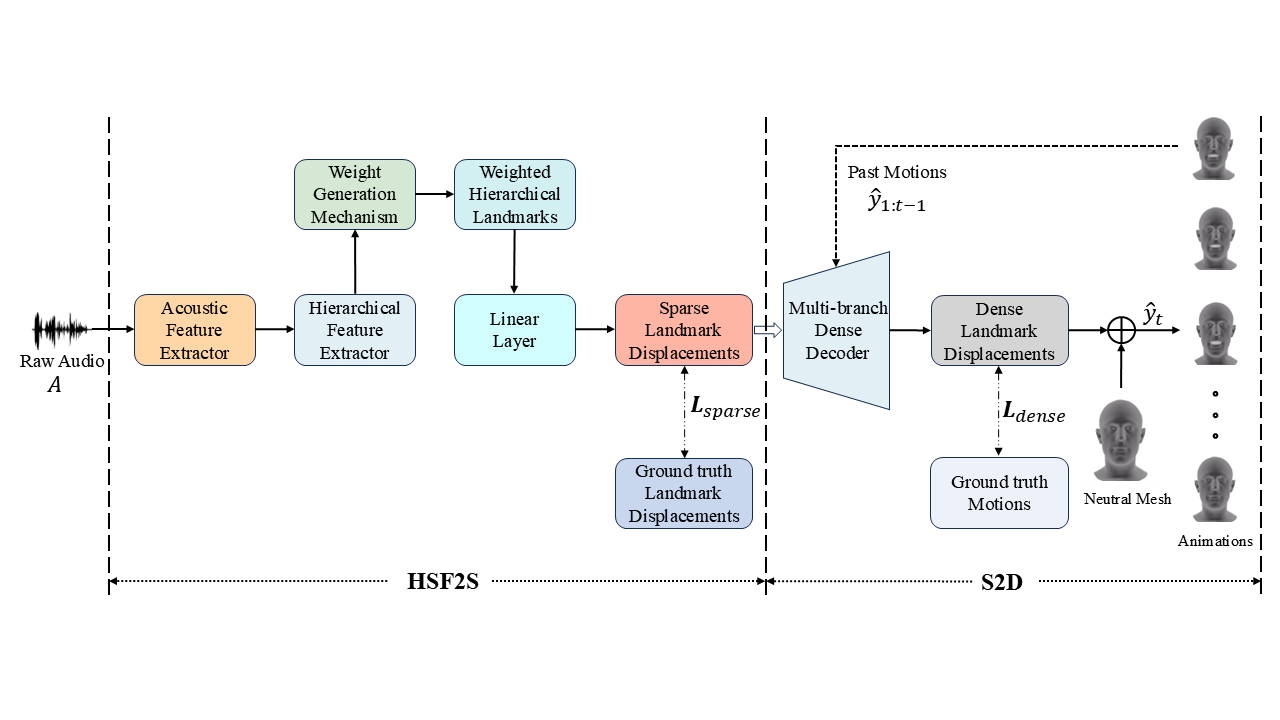
Pipeline of our proposed HiSTalk. HiSTalk, learning the correlations between HSF and facial landmarks, receives a raw audio 𝐴 as input and generates a sequence of
3D facial animation from sparse to dense landmark displacements. The Acoustic Feature Extractor is Wav2Vec 2.0, and the Hierarchical Feature Extractor follows the
SpeechFormer++ block. The weighted generation mechanism calculates the contribution of frame-level, phoneme-level, word-level, and utterance-level speech features
to landmark displacements. Then S2D uses a Transformer-based decoder to generate the dense landmark displacement sequences for rendering the animation.
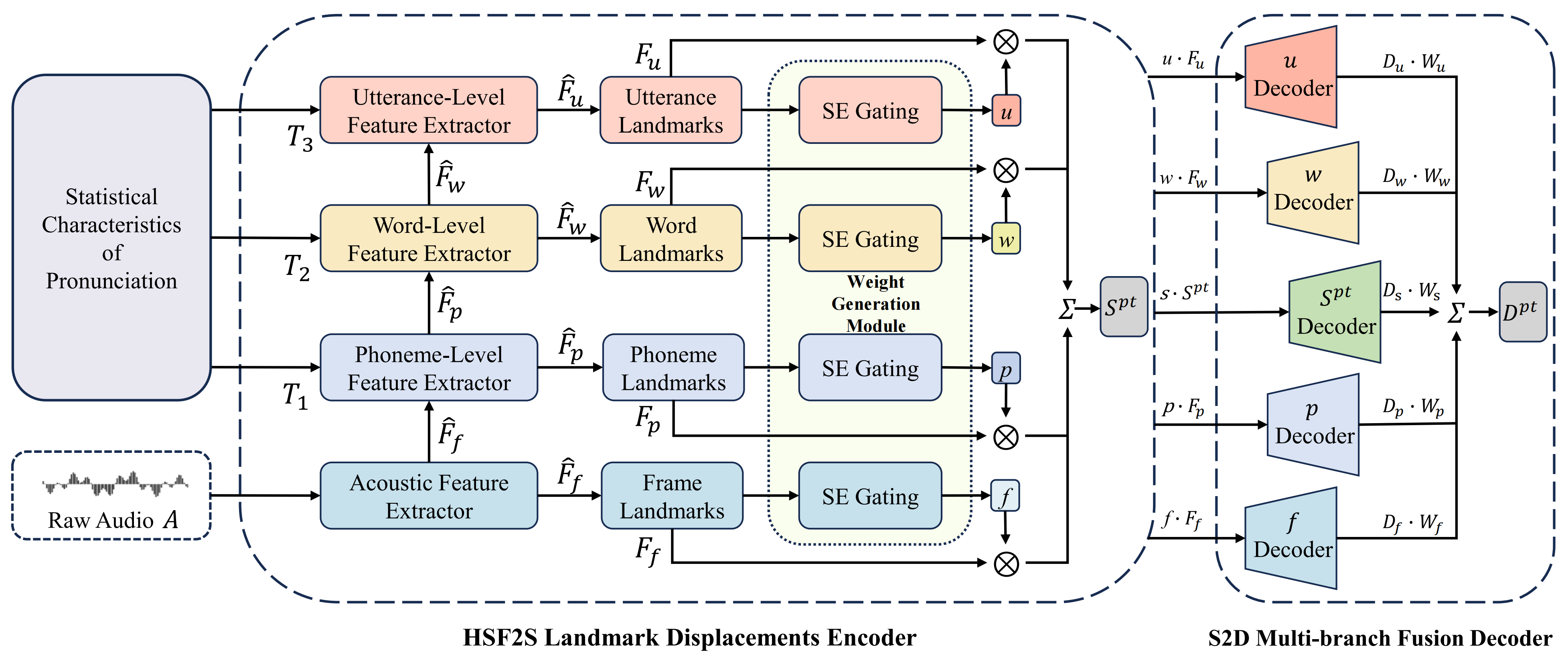
Overview of hierarchical speech feature-based landmark displacements encoder with a weighted generation module.
BibTeX
@article{2025histalk,
title={HiSTalk: Hierarchical Speech Feature-based Landmark Displacements for 3D Talking Head Animation},
author={},
journal={arXiv preprint arXiv},
year={2025}
}